




フレーム選択の要否と対象XPathの判断について + α
(利用環境)
Win10 Pro
WinActor ver7.3
フレーム構造のWebページの操作を自動化する際、『フレーム選択』のライブラリを利用して対象フレームを選択する必要がある認識でいますが、
①『フレーム選択』を利用しなければならないか
②利用時に『childの場合のXPath』に何のXPathを設定すべきなのか の二点が分かっておりません
具体の内容で申し訳ないのですが、例えば下記サイトで検索結果一覧を操作したい場合、フレーム選択の要否と対象XPathの判断をするとしたらどのように行われていますでしょうか。
(東京証券取引所の提供しているサービスです)
下記画像の通り、検索結果の表題をクリックや表の一括取得を行いたいと考えていますが、エラーが発生している状態です。
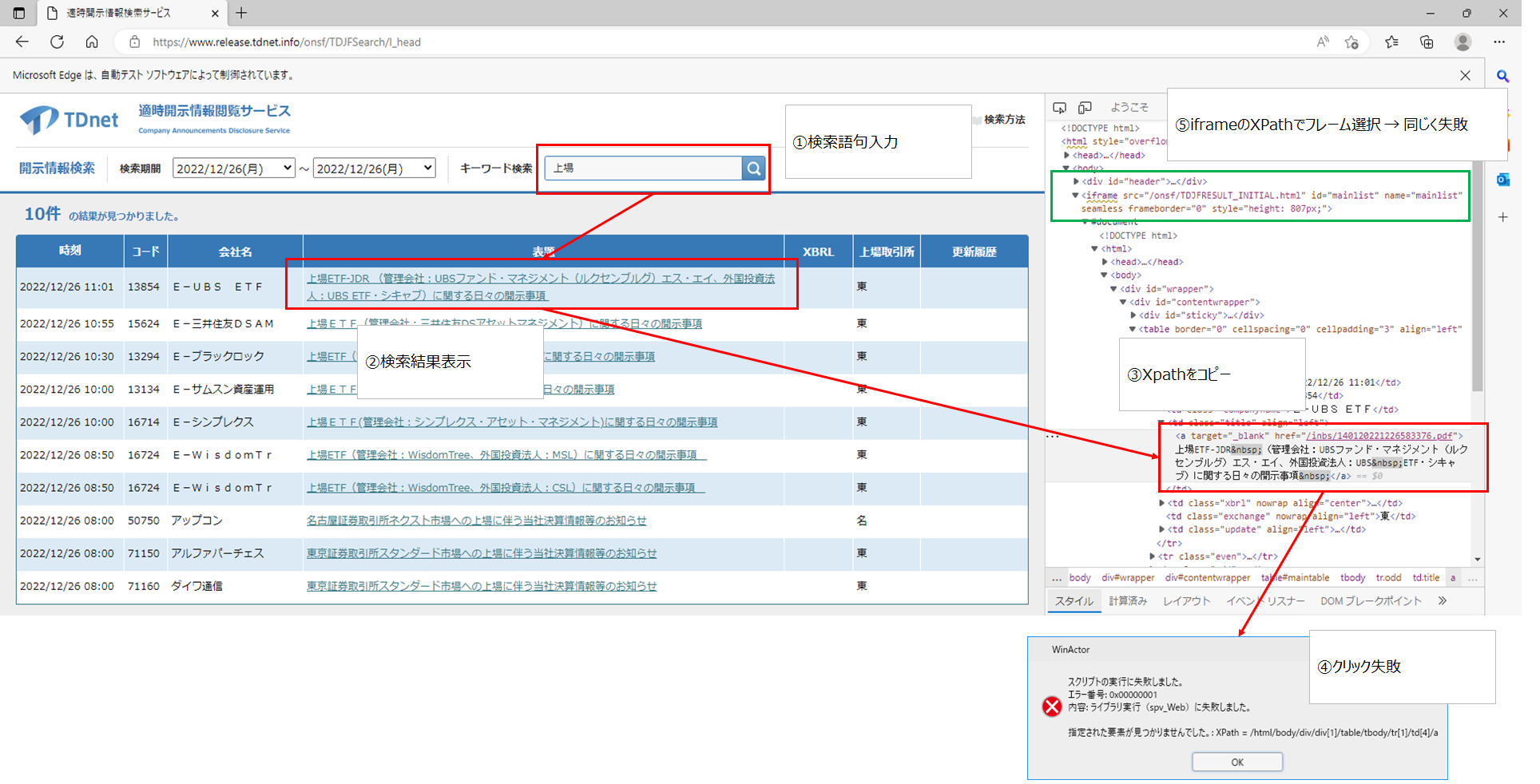
・全ての検索結果に対して同じ作業(保存)を行いたいが、表の一括取得ができない
・表題リンクのクリックができるか試してみる → クリック不可
・ソースにiframeの文字列がある → 含まれるXPath(2つ)をchildに入れてみたが結果変わらず
※親 → 子の順番で設定しています
・自動記録ではフレーム関連のノードが作成されず、記録されたフローを実行してもエラーが発生しました
(以下横道です)
表の(一括)取得ができない場合、画像にある『10件の結果が見つかりました』の『10』を取得して繰り返しの回数に利用したいと思っています。
この箇所のソースの表記は『<span id="result">10件</span>』なのですが、このXPathを特定したうえでこの『10件』を取得する方法はないのでしょうか。
解決方法があればご教示くださいますと幸いです。
どうぞよろしくお願い致します。
この質問は解決済みのためクローズされています。
ICT ベストアンサーとして選択しました
回答とコメントは、会員登録(無料)で閲覧できるようになります。
新規登録