




「AI inside 株式会社の「DX Suite」をWeb API経由で利用し、ファイルアップロードとOCR結果取得を行うサンプルシナリオ」でのエラーについて
「AI inside 株式会社の「DX Suite」をWeb API経由で利用し、ファイルアップロードとOCR結果取得を行うサンプルシナリオ」を使用して、PDFファイルの読み取りを行っています。
これまでは問題なく動いていたのですが、今回ファイルサイズの大きいPDFの読み取りを行おうとしたところ、下記のエラーとなりました。
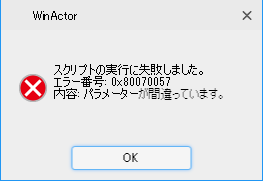
エラーになる箇所は一番最初の「6:読取ページ追加」です。
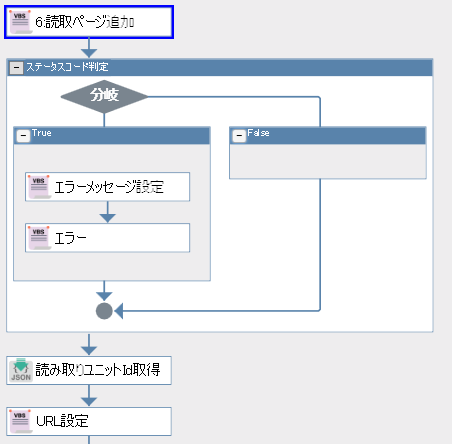
いろいろなファイルサイズやページ数のPDFで試してみたところ、ページ数には関係なく、サイズが約260MBを超えているものを読み取ろうとするとエラーになるようでした。(ファイル名とページ数が同じであっても、サイズが257MBのものはエラーにならず、260.1MBのものはエラーとなりました)
また、エラーになるPDFファイルも、RPAを使用せずに手動でアップロードした場合は、正常に読み取りできました。
そもそも推奨サイズ(1ファイルにつき20MB以下)を大幅に超えているので、諦めてサイズの大きいものは複数に分割して処理するしかないのかも……とも思ってはいるのですが……。
もし他にエラーを回避する方法がありましたら、教えていただけますでしょうか。
よろしくお願いいたします。
WinActorのバージョン:7.2.0
この質問は解決済みのためクローズされています。
トゥーティッキ ベストアンサーとして選択しました
回答とコメントは、会員登録(無料)で閲覧できるようになります。
新規登録