




【情報共有】最近「辞書の作成と検索を行うサンプルシナリオ」で、ようやく辞書について理解できました。
5/27日にNTTATのサンプルシナリオで、「辞書の作成と検索を行うサンプルシナリオ」がリリースされていました。
内容を確認して、ようやく「辞書」について理解できたので、情報共有と思い、投稿しました。
サンプルシナリオでは、日本郵便Webページよりダウンロードした郵便番号データCSVファイルを使用して、辞書データをCsvデータを加工しながら30件弱のデータを辞書に取り込む作業をしていて、その部分の繰り返しだけでそれなりの時間を費やすので、果たして実用的なのか?と思いましたが、辞書データ自体が出来上がっているものを取り込む分については、さほど時間がかからないので、いろいろな部分に活用できるように思いました。
ライブラリの「03_変数→02_辞書と配列」にあるライブラリで、
配列のほうについては、よく質問にも上がっていましたが、辞書についてはなかなか明確に自分も理解できていませんでした。
1:1のデータの対の連続、で、1個目が「キー」、2個目が「情報(データ)」という決まりの中での情報の集まりを、メモリ上に保持しておける、ってことなんだと思います。
で、必要に応じて、キーをもとにデータをピックアップできるようです。
辞書の機能を使わなくても、Excelで表を用意しておいて、検索したりで、代用できますが、辞書も使えれば、役に立ちそうです。
機能を理解するためだけに、簡単なシナリオを作成してみました。
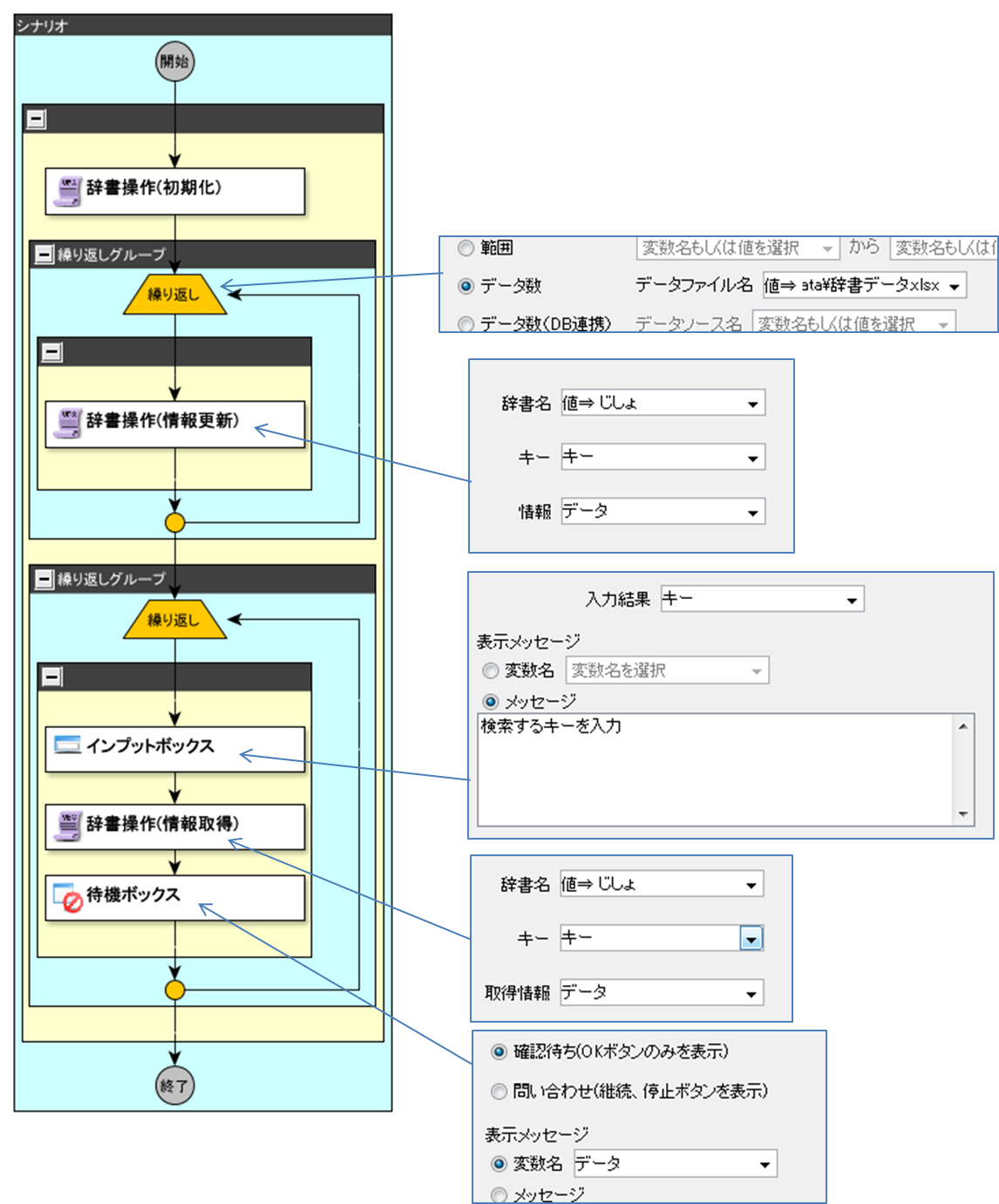
2個目の繰り返しは無限ループです。
辞書データのExcelファイルはこんな感じです。
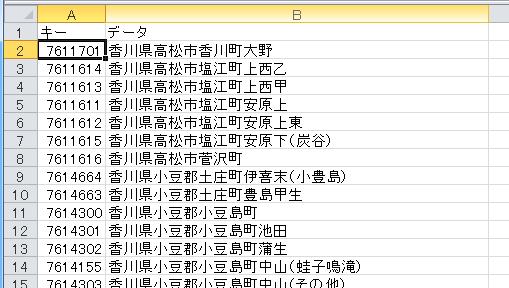
サンプルシナリオで使用していた辞書が完成したものを、ダンプ(出力)したものを流用しました。
インプットボックスにキーの郵便番号を正確に入力すると、待機ボックスに、キーに対応するデータが表示されます。
最初の辞書操作(情報更新)が、それなりにぱぱっと過ぎてくれますので、これなら実用に耐えうるな、と思いました。
ご参考まで。
また、「このサンプルシナリオがすごく役に立ってます」というおすすめのシナリオがありましたら、ぜひご回答ください。
Zawawa 新しいコメントを投稿
回答とコメントは、会員登録(無料)で閲覧できるようになります。
新規登録