




【DX013】読取範囲の詳細設定における辞書設定_補完編
こんにちは、NTTデータ 技術支援チームです。
いつもユーザーフォーラムをご利用いただき、ありがとうございます。
皆さまは「1(イチ)と読み取たいのにI(アイ)と誤読してしまう」「0(ゼロ)と読み取りたいのにO(オー)と誤読してしまう」
こういった経験はございませんか?
このように誤読しやすい文字は、ユーザー辞書を使って補完することで正しく読み取れるようになります。
例として、「製品コード [A1000](エーイチ) を読み取りたいが、[AI000](エーアイ) と誤読してしまう」
場合の設定をしてみましょう!
①対象データについてユーザ辞書を作成する(※参照キーが対象となります)
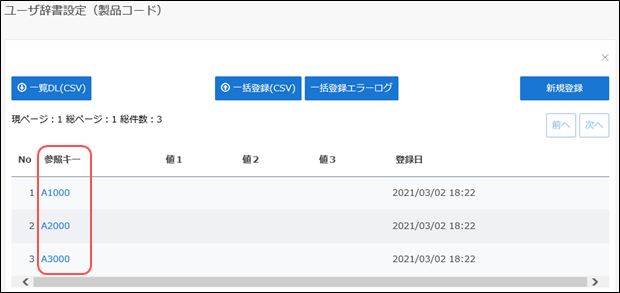
②該当項目の辞書設定画面で各値を設定します
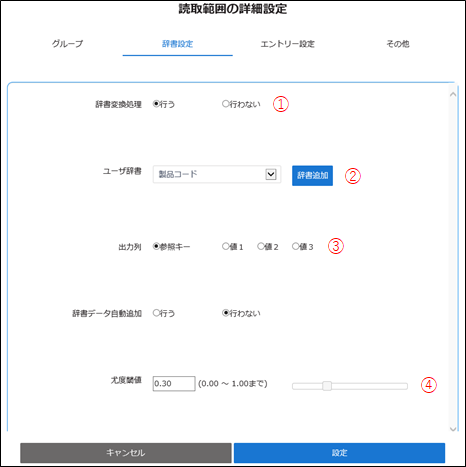
①辞書変換処理 [行う] を選択
②参照するユーザ辞書を選択
③出力列 [参照キー] を選択
④尤度閾値を設定
《尤度閾値》
尤度閾値とは、読み取った値とユーザ辞書に登録されたデータの一致率を表す値です。
ユーザ辞書に登録した文字列で出力するために必要な、一致率を設定することができます。(例)
尤度閾値:1.00 → 100%一致した場合
尤度閾値:0.50 → 50%一致した場合
実際に読取をしてみましょう!
・帳票イメージ
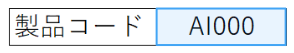
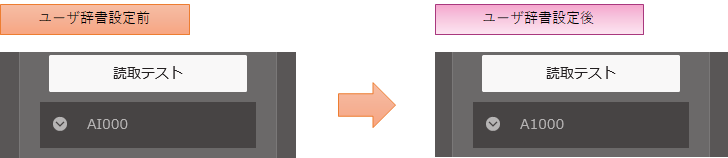
「AI000」(エーアイ)と読み取られていたものが 補完機能で「A1000」(エーイチ)と読み取られるようになりました!
以上、ご参考になれば幸いです。
<本投稿の動作環境>
DX Suite 1.0(クラウド版) v1.32.0
<お願い>
本投稿に関しての問合わせにつきましては、
恐れ入りますがコメントではなく、個別問合せにてお願いいたします。
技術支援チーム44 質問の編集
回答とコメントは、会員登録(無料)で閲覧できるようになります。
新規登録