




【DX115】Intelligent OCRの精度向上術~前編~
こんにちは、NTTデータ技術支援チームです。
いつもユーザーフォーラムをご利用いただき、ありがとうございます。
前回はElastic Sorterの仕分け精度向上についてご案内いたしました。
今回は、Intelligent OCR の読取精度向上のための設定方法について、前後編に分けてご紹介いたします。
Elastic Sorter編はこちら
■帳票定義編
「読取範囲の指定」にて作成したワークフローの読取精度を上げる方法として、以下の方法があります。
①読取項目の作成方法を工夫する
読取範囲の余白部分を狭くし、余白を含めないようにしたり、
あえて帳票上の罫線などを範囲に含めるなど、読取範囲を調整することで文字が際立ち、精度が向上する場合があります。
マークシート、チェックボックスなどの塗りつぶしの認識にも有効です。
②読取条件の指定を変更する
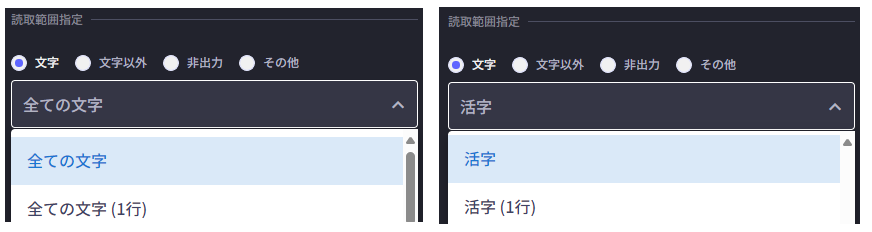
Intelligent OCRには26種類の読取条件がありますが、以下のふたつは特にAIによる学習データが多い読取条件です。
・手書き文字を読み取る場合
「全ての文字」、「全ての文字(1行)」
・印字を読み取る場合
「活字」、「活字(1行)」
読み取りたい文字に合わせて一度お試しいただき、読取精度結果により他の条件を選び調整してください。
③除外範囲を設定する
読取不要な部分を読取除外することで、読取範囲内の文字が際立ち、精度が向上する場合がございます。

■手書き編
帳票に文字を記入する際に、文字の書き方などに気を付けていただくことで、読取精度が向上する場合もございます。

①文字列は空白を開けずに記入する
Intelligent OCRは前後の文字のつながりを類推して単語に応じた読取結果を返します。
文字列に空白がある場合、前後の文字とのつながりを類推せずに読取結果を返す場合があるので、
空白を開けずに記入する事で、読み取り精度が向上する場合があります。
②文字の特徴を踏まえた記入をする
「1(いち)」と「l(エル)」、「0」(ゼロ)と「O」(オー)などのように、
人の目で見ても判断が難しい文字は、帳票の状態によっては誤読するケースがあります。
「0(ゼロ)は縦に長くなるように記入する」など、文字ごとの特徴を踏まえて記入する事で読み取り精度が向上する場合があります。
また、データ加工「文字列変換(部分一致)」や「ユーザ辞書置換」などを利用して、
誤読した文字を出力したい文字に変換する方法もございます。
③文字を水平に記入する
DX Suite では読取範囲内を水平に左から右、上から下へと読み取りを行います。
文字が斜めに記入されていると、行検出が適切に行えず、うまく読取を行えない場合がございます。
(本来1行の文字列を複数行として読み取ってしまうなど)
このため、文字をなるべく平行に記入することで読取を行いやすくなります。
以上、ご参考になれば幸いです。
<本投稿の動作環境>
DX Suite(クラウド版)v1.145.0
<お願い>
本投稿に関しての問合せにつきましては、
恐れ入りますがコメントではなく、個別問合せにてお願いいたします。
技術支援チーム66 質問の投稿
回答とコメントは、会員登録(無料)で閲覧できるようになります。
新規登録