




ExcelとCSVのデータ照合の正確性を高めるには
お世話になっております。
前回の質問に対する回答をまだ出来ておりませんが(帰宅してから行います)、
質問は社内でないと出来ない&顧客からこの件の原因究明を急かされている為、続けて質問を失礼致します。
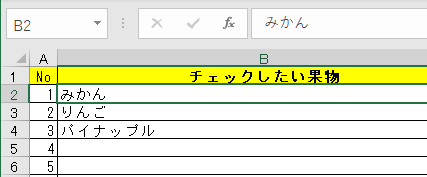
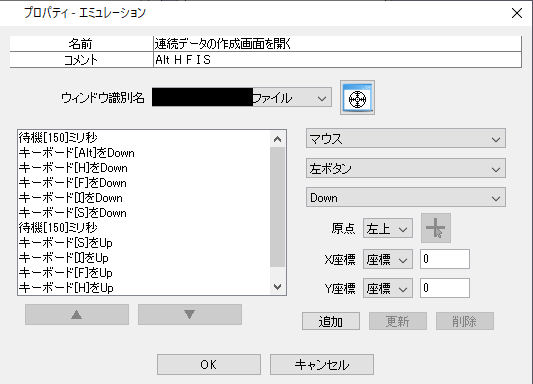
以下のExcelの「チェックしたい果物」に該当するデータ値(画像1)が、
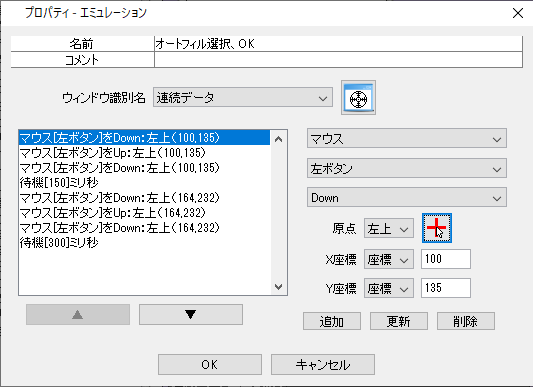
CSVのY列(画像2)に1つ以上存在するかのデータ照合をRPAで行っています。
CSVにExcelの値が存在する場合はTrue、存在しない場合はFalseの処理を行います。
このデータ照合にて、稀に
「Trueの結果値になり得るはずなのに、実際のRPA結果はFalseになっている」という不具合が発生します。
事象は一部のCSVのみで発生し、全CSVで必ず毎回発生するものではありません。
また、発生するタイミングも確定ではありません。
(画像1)と(画像2)の値(「みかん」や「りんご」)は完全一致している状態です。
半角全角の差異・先頭末尾の空白有無による差異はありませんでした。
(画像1)
(画像2)

CSVは顧客データごとに出力しています。Excelは固有のファイルです。
RPAの動きは、CSV出力→データ照合→CSV出力→……になります。
データ照合を行う為に、Excel関数を2つ使用し、以下のセルに毎回RPAで設定しています。
①(画像2)のAA6セル
→ SUM(AA8:AA5000)
②(画像2)のAA8セル
→ COUNTIF([画像1.xlsx]Sheet1!$B$2:[画像1.xlsx]Sheet1!$B$10,JIS(Y8))
AA8セル設定後→AA8:AA5000で範囲設定・オートフィルを行っています。
JIS関数が入っているのは、CSVの値が半角値で入りうる可能性があることから行っています。(基本は全角で入る)
①②の関数セット後、①の値を取得 → 1以上であれば「True」、0なら「False」としています。
不具合が発生してもRPAは正常終了しているため、フロー中にエラーの発生はないことから、
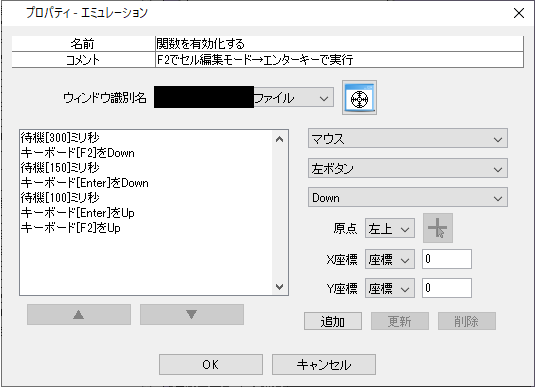
エミュレーションが失敗、または設定したExcel関数がうまく動けていない?のかなと推測しています。
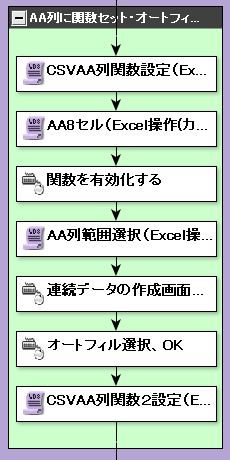
現RPAのフロー(該当部分)は下に添付します。
知りたいことは以下の内容になります。
・本件のような「実際はTrue結果なのにRPAでたまにFalseと誤認する」事象が発生する理由・その対策
・現フローの正確性を高める(=本件の事象が完全に発生しないようにする)ためには、どう改善すべきか
・本件の事象発生時のリカバリ方法もしあれば
(誤認していることをRPAで自認させることは難しいと思っています……)
RPA誤認が許されないデータ照合処理なので、どのように正確性を高めるべきか悩んでいます。
それとも、このような失敗が一切許されない(RPA自身が誤認・失敗していると気付きにくい)業務処理はRPAに向いていなかったのでしょうか……。
よろしくお願い致します。
(画像3)
anothersolution 回答した質問
回答とコメントは、会員登録(無料)で閲覧できるようになります。
新規登録